How to Delete Old Data from an Azure Storage Table: Part 2
/In part 1 of this series, we explored how to delete data from an Azure Storage Table and covered the simple implementation of the AzureTablePurger tool.
The simple implementation seemed way too slow to me, and took a long time when purging a large amount of data from a table. I figured if I could execute many requests to Table Storage in parallel, it should perform a lot quicker.
To recap, our code fundamentally does 2 things:
Enumerates entities to be deleted
Delete entities using batch operations on Azure Table Storage
Since there could be a lot of data to enumerate and delete, there is no reason why we can't execute these operations parallel.
Since the AzureTablePurger is implemented as a console app, we could parallelize the operation by spinning up multiple threads, or multiple Tasks, or using the Task Parallel Library to name a few ways. The latter is the preferred way to build such a system in .NET 4 and beyond as it simplifies a lot of the underlying complexity of building multi-threaded and parallel applications.
I settled on using the Producer/Consumer pattern backed by the Task Parallel Library.
Producer/Consumer Pattern
Put simply, the Producer/Consumer pattern is where you have 1 thing producing work and putting it in a queue, and another thing taking work items from that queue and actually doing the work.
There is a pretty straightforward way to implement this using the BlockingCollection in .NET.
Producer
In our case, the Producer is the thing that is querying Azure Table Storage and queuing up work:
/// <summary> /// Data collection step (ie producer). /// /// Collects data to process, caches it locally on disk and adds to the _partitionKeyQueue collection for the consumer /// </summary> private void CollectDataToProcess(int purgeRecordsOlderThanDays) { var query = PartitionKeyHandler.GetTableQuery(purgeRecordsOlderThanDays); var continuationToken = new TableContinuationToken(); try { // Collect data do { var page = TableReference.ExecuteQuerySegmented(query, continuationToken); var firstResultTimestamp = PartitionKeyHandler.ConvertPartitionKeyToDateTime(page.Results.First().PartitionKey); WriteStartingToProcessPage(page, firstResultTimestamp); PartitionPageAndQueueForProcessing(page.Results); continuationToken = page.ContinuationToken; // TODO: temp for testing // continuationToken = null; } while (continuationToken != null); } finally { _partitionKeyQueue.CompleteAdding(); } }
We start by executing a query against Azure Table storage. Like with our simple implementation, this will execute a query and obtain a page of results, with a maximum of 1000 entities. We then take the page of data and break it up into chunks for processing.
Remember, to delete entities in Table Storage, we need the PartitionKey and RowKey. Since we could be dealing with a large amount of data, it doesn't make sense to store this PartitionKey and RowKey information in memory, otherwise we'll start running out of space. Instead, I decided to cache this on disk in one file for each PartitionKey. Inside the file, we write one line for each PartitionKey + RowKey combination that we want to delete.
We also add a work item to an in-memory queue that our consumer will pull from. Here’s the code:
/// <summary> /// Partitions up a page of data, caches locally to a temp file and adds into 2 in-memory data structures: /// /// _partitionKeyQueue which is the queue that the consumer pulls from /// /// _partitionKeysAlreadyQueued keeps track of what we have already queued. We need this to handle situations where /// data in a single partition spans multiple pages. After we process a given partition as part of a page of results, /// we write the entity keys to a temp file and queue that PartitionKey for processing. It's possible that the next page /// of data we get will have more data for the previous partition, so we open the file we just created and write more data /// into it. At this point we don't want to re-queue that same PartitionKey for processing, since it's already queued up. /// </summary> private void PartitionPageAndQueueForProcessing(List<DynamicTableEntity> pageResults) { _cancellationTokenSource.Token.ThrowIfCancellationRequested(); var partitionsFromPage = GetPartitionsFromPage(pageResults); foreach (var partition in partitionsFromPage) { var partitionKey = partition.First().PartitionKey; using (var streamWriter = GetStreamWriterForPartitionTempFile(partitionKey)) { foreach (var entity in partition) { var lineToWrite = $""; streamWriter.WriteLine(lineToWrite); Interlocked.Increment(ref _globalEntityCounter); } } if (!_partitionKeysAlreadyQueued.Contains(partitionKey)) { _partitionKeysAlreadyQueued.Add(partitionKey); _partitionKeyQueue.Add(partitionKey); Interlocked.Increment(ref _globalPartitionCounter); WriteProgressItemQueued(); } } }
A couple of other interesting things here:
The queue we're using is actually a BlockingCollection, which is an in-memory data structure that implements the Producer/Consumer pattern. When we put things in here, the Consumer side, which we’ll explore below, takes them out
It's possible (and in fact likely) that we'll run into situations where data having the same PartitionKey ends up spanning multiple pages of results. For example, at the end of page 5, we have 30 records with PartitionKey = 0636213283200000000, and at the beginning of page 6, we have a further 12 records with the same PartitionKey. To handle this situation, when processing page 5, we create a file 0636213283200000000.txt to cache all of the PartitionKey + RowKey combinations and add 0636213283200000000 to our queue for processing. When we process page 6, we realize we already have a cache file 0636213283200000000.txt, so we simply append to the file it. Since we have already added 0636213283200000000 to our queue for processing. We don’t want to have duplicate items in the queue, otherwise we'd end up with multiple consumers each trying to consume or process the same cache file, which doesn't make sense. Since there isn't a built-in way to prevent us from adding duplicates into a BlockingCollection, the easiest option is to simply maintain a parallel data structure (in this case a HashSet) so we can keep track of and quickly query items we've added into the queue to ensure we're not going to add the same PartitionKey into the queue twice
We're using Interlocked.Increment() to increment some global variables. This ensures that when we're running multi-threaded, each thread can reliably increment the counter without running into any threading issues. If you're wondering why to use Interlocked.Increment() vs lock or volatile, there is a great discussion on the matter on this Stack Overflow post.
Consumer
The consumer in this implementation is responsible for actually deleting the entities we want to delete. It is given the PartitionKey that it should be dealing with, reads the cached PartitionKey + RowKey combination from disk, and constructs batches of no more than 100 operations at a time and executes them against the Table Storage API:
/// <summary> /// Process a specific partition. /// /// Reads all entity keys from temp file on disk /// </summary> private void ProcessPartition(string partitionKeyForPartition) { try { var allDataFromFile = GetDataFromPartitionTempFile(partitionKeyForPartition); var batchOperation = new TableBatchOperation(); for (var index = 0; index < allDataFromFile.Length; index++) { var line = allDataFromFile[index]; var indexOfComma = line.IndexOf(','); var indexOfRowKeyStart = indexOfComma + 1; var partitionKeyForEntity = line.Substring(0, indexOfComma); var rowKeyForEntity = line.Substring(indexOfRowKeyStart, line.Length - indexOfRowKeyStart); var entity = new DynamicTableEntity(partitionKeyForEntity, rowKeyForEntity) { ETag = "*" }; batchOperation.Delete(entity); if (index % 100 == 0) { TableReference.ExecuteBatch(batchOperation); batchOperation = new TableBatchOperation(); } } if (batchOperation.Count > 0) { TableReference.ExecuteBatch(batchOperation); } DeletePartitionTempFile(partitionKeyForPartition); _partitionKeysAlreadyQueued.Remove(partitionKeyForPartition); WriteProgressItemProcessed(); } catch (Exception) { ConsoleHelper.WriteWithColor($"Error processing partition ", ConsoleColor.Red); _cancellationTokenSource.Cancel(); throw; } }
After we finish processing a partition, we remove the temp file and we remove the PartitionKey from our data structure that is keeping track of the items in the queue, namely the HashSet _partitionKeysAlreadyQueued. There is no need to remove the PartitionKey from the queue, as that already happened when this method was handed the PartitionKey.
Note:
This implementation is reading all of the cached data into memory at once, which is fine for the data patters I was dealing with, but we could improve this by doing a streamed read of the data to avoid reading too much information into memory
Executing both in Parallel
To string both of these together and execute them in Parallel, here's what we do:
public override void PurgeEntities(out int numEntitiesProcessed, out int numPartitionsProcessed) { void CollectData() void ProcessData() { Parallel.ForEach(_partitionKeyQueue.GetConsumingPartitioner(), new ParallelOptions { MaxDegreeOfParallelism = MaxParallelOperations }, ProcessPartition); } _cancellationTokenSource = new CancellationTokenSource(); Parallel.Invoke(new ParallelOptions { CancellationToken = _cancellationTokenSource.Token }, CollectData, ProcessData); numPartitionsProcessed = _globalPartitionCounter; numEntitiesProcessed = _globalEntityCounter; }
Here we're defining 2 Local Functions, CollectData() and ProcessData(). CollectData will serially execute our Producer step and put work items in a queue. ProcessData will, in parallel, consume this data from the queue.
We then invoke both of these steps in parallel using Parallel.Invoke() which will wait for them to complete. They'll be deemed completed when the Producer has declared there is no more things it is planning to add via:
_partitionKeyQueue.CompleteAdding();
and the Consumer has finished draining the queue.
Performance
Now we're doing this in parallel, it should be quicker, right?
In theory, yes, but initially, this was not the case:
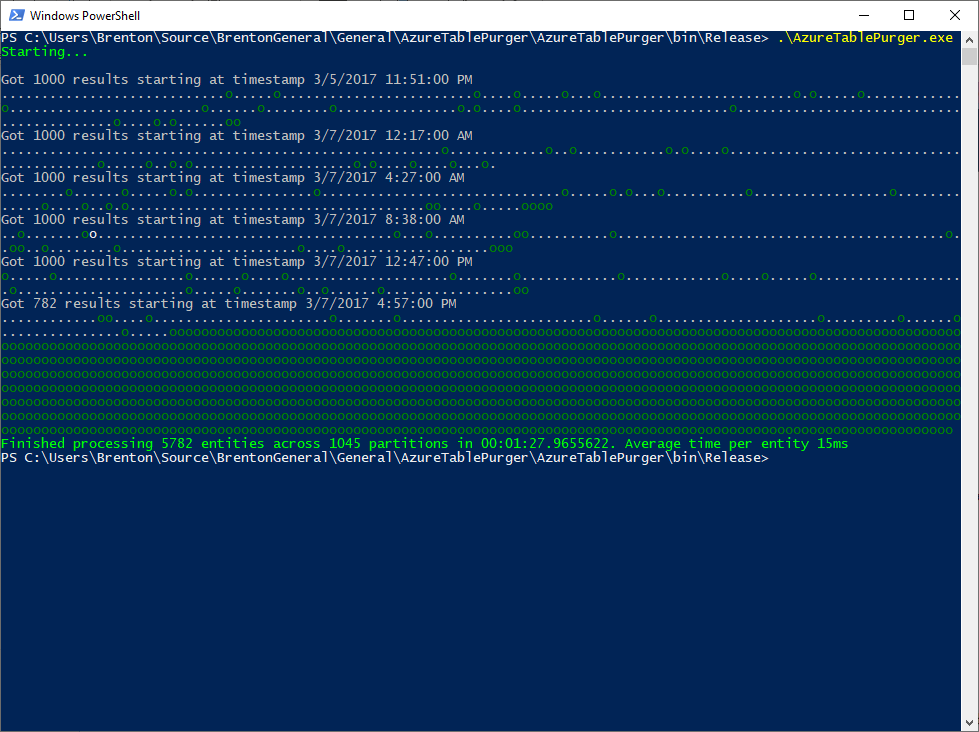
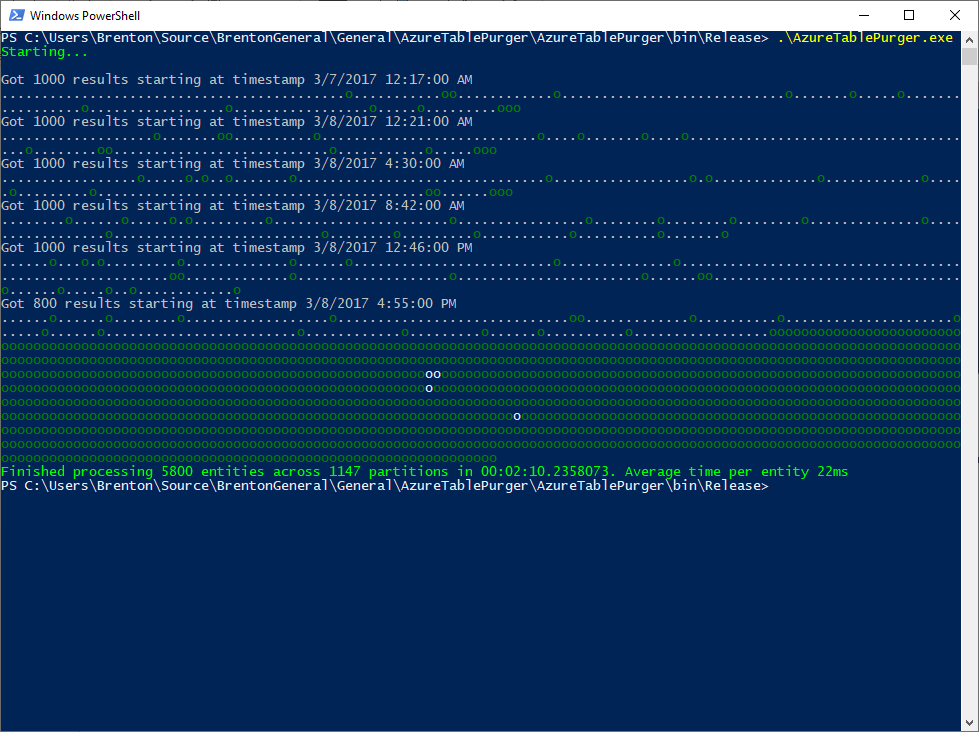
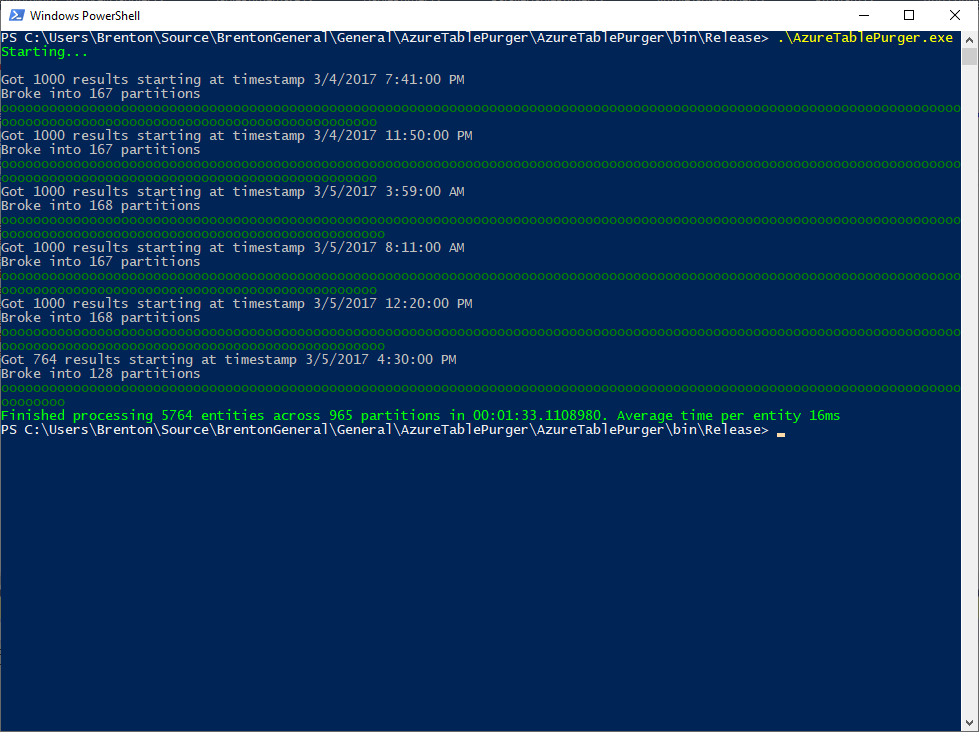
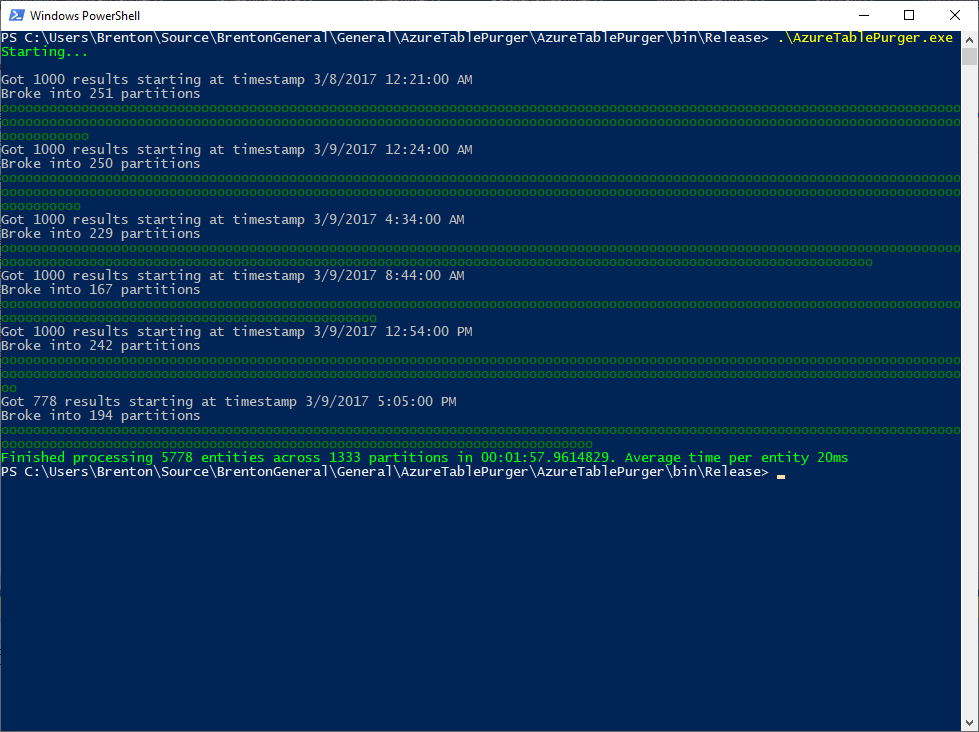
From the 2 runs above you can visually see how the behavior differs from the Simple implementation: each "." represents a queued work item, and each "o" represents a consumed work item. We're producing the work items much quicker than we can consume them (which is expected), and once our production of work items is complete, then we are strictly consuming them (also expected).
What was not expected was the timing. It's taking approximately the same time on average to delete an entity using this parallel implementation as it did with the simple implementation, so what gives?
Turns out I had forgotten an important detail - adjusting the number of network connections available by using the ServicePointManager.DefaultConnectionLimit property. By default, a console app is only allowed to have a maximum of 2 concurrent connections to a given host. In this app, the producer is typing up a connection while it is hitting the API and obtaining PartitionKeys + RowKeys of entities we want to delete. There should be many consumers running at once sending deletion requests to the API, but there is only 1 connection available for them to share. Once all of the production is complete, then we'd free up that connection and now have 2 connections available for consumers. Either way, we're seriously limiting our throughput here and defeating the purpose of our much fancier and more complicated Parallel solution which should be quicker, but instead is running at around the same pace as the Simple version.
I made this change to rectify the problem:
private const int ConnectionLimit = 32; public ParallelTablePurger() { ServicePointManager.DefaultConnectionLimit = ConnectionLimit; }
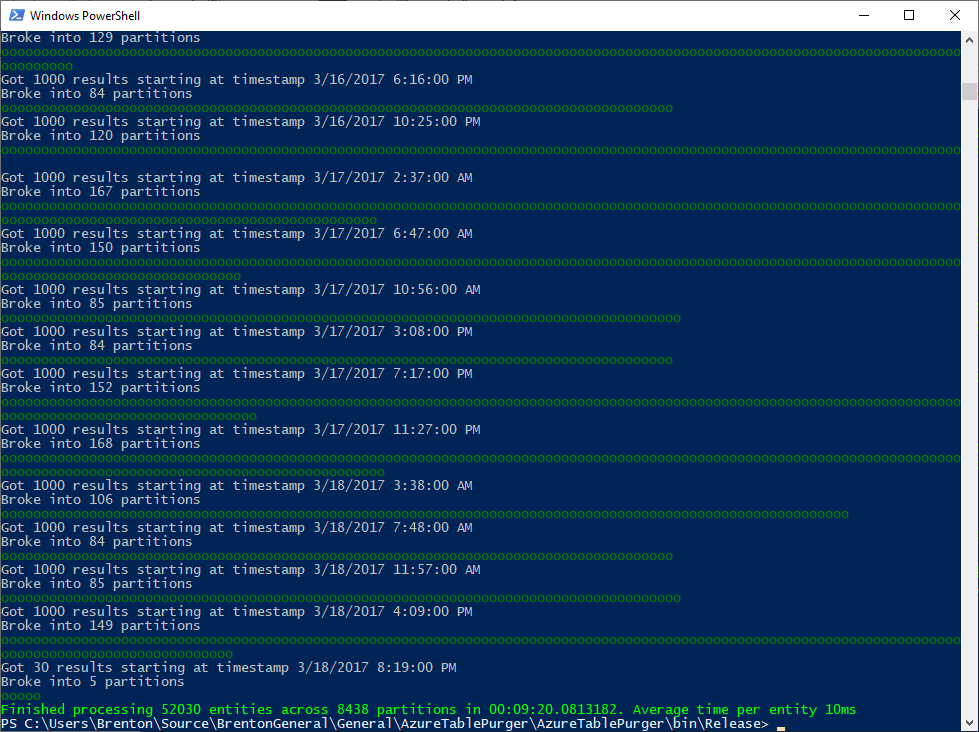
Now, we're allowing up to 32 connections to the host. With this I saw the average execution time drop to around 5-10ms, so somewhere between 2-4x the speed of the simple implementation.
I also tried 128 and 256 maximum connections, but that actually had a negative effect. My machine was a lot less responsive while the app was running, and average deletion times per entity were in the 10-12ms range. 32 seemed to be somewhere around the sweet spot.
For the future: turning it up to 11
There are many things that can be improved here, but for now, this is good enough for what I need.
However, if we really wanted to turn this up to 11 and make it a lot quicker, a lot more efficient and something that just ran constantly as part of our infrastructure to purge old data from Azure tables, we could re-build this to run in the cloud.
For example, we could create 2 separate functions: 1 to enumerate the work, and a second one that will scale out to execute the delete commands:
1. Create an Azure Function to enumerate the work
As we query the Table Storage API to enumerate the work to be done, put the resulting PartitionKey + RowKey combination either into a text file on blob storage (similar to this current implementation), or consider putting it into Cosmos DB or Redis. Redis would probably be the quickest, and Blob Storage probably the cheapest, and has the advantage that we avoid having to spin up additional resources.
Note, if we were to deploy this Azure Function to a consumption plan, functions have a timeout of 10 minutes. We'd need to make sure that we either limit our run to less than 10 minutes in duration, or we can handle being interrupted part way through and pick up where we left the next time the function runtime calls our functio
2. Create an Azure Function to do the deletions
After picking up an item from the queue, this function would be responsible for reading the cached PartitionKey + RowKey and batching up delete operations to send to Table Storage. If we deployed this as an Azure Function on a consumption plan, it will scale out to a maximum of 200 instances, which should be plenty for us to work through the queue of delete requests in a timely manner, and so long as we're not exceeding 20,000 requests per second to the storage account, we won't hit any throttling limits there.
Async I/O
Something else we'd look to do is to make the I/O operations asynchronous. This would probably provide some benefits in our console app implementation, although I'm not sure how much difference it would really make. I decided against async I/O for the initial implementation, since it doesn't play well with Parallel.ForEach (check out this Stack Overflow post or this GitHub issue for some more background), and would require a more complex implementation to work.
With a move to the cloud and Azure Functions, I'm not sure how much benefit async I/O would have either, since we rely heavily on scaling out the work to different processes and machines via Azure Functions. Async is great for increasing throughput and scalability, but not raw performance, which is what our goal is here.
Side Note: Durable Functions
Something else which is pretty cool and could be useful here is Azure Durable functions. This could be an interesting solution to this problem as well, especially if we wanted to report back on aggregate statistics like how long it took to complete all of the work and average time to delete a specific record (ie the fan-in).
Conclusion
It turns out the Parallel solution is quicker than the Simple solution. Feel free to use this tool for your own purposes, or if you’re interested in improving it, go ahead and fork it and make a pull request. There is a lot more that can be done :)